|
Our research interests are to develop deep learning algorithms for 3D computer vision problems and create end-to-end solution pipelines. |

|
With advances in deep learning model training strategies, the training of Point cloud classification methods is significantly improving. For example, PointNeXt, which adopts prominent training techniques and InvResNet layers into PointNet++, achieves over 7% improvement on the real-world ScanObjectNN dataset. However, most of these models use point coordinates features of neighborhood points mapped to higher dimensional space while ignoring the neighborhood point features computed before feeding to the network layers. In this paper, we revisit the PointNeXt model to study the usage and benefit of such neighborhood point features. |

|
We propose the use of neighbor projections along with object projections to learn finer local structural information. SimpleView++ concatenates features from orthogonal perspective projections at object and neighbor levels with encoded features from the point cloud. |
|
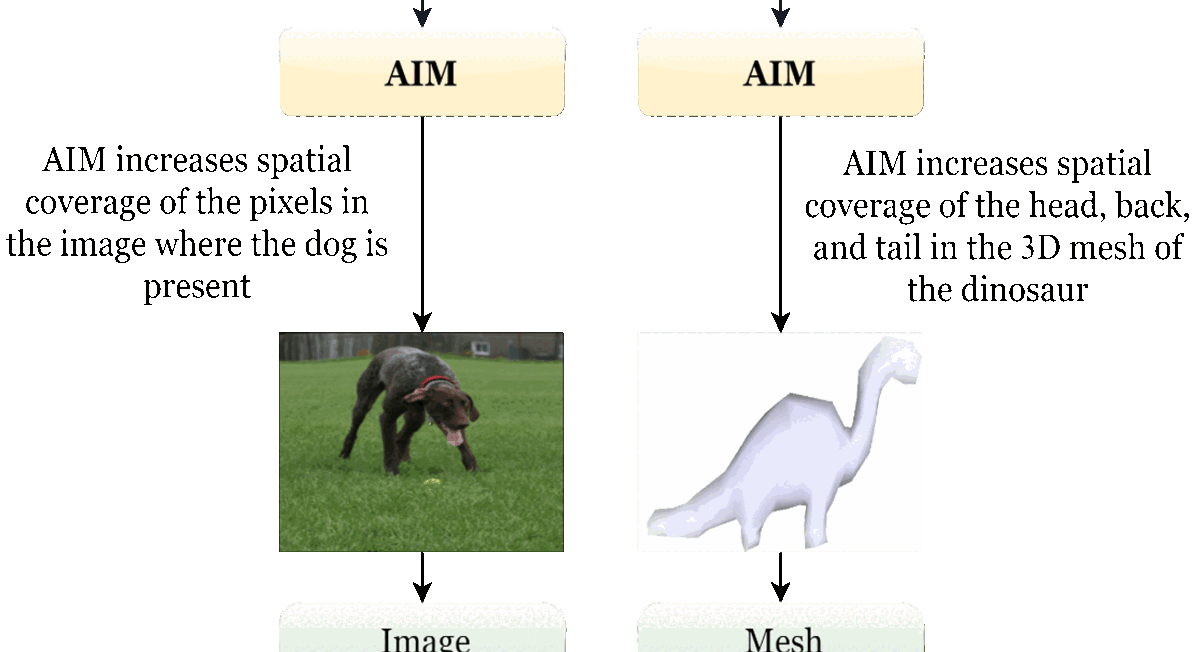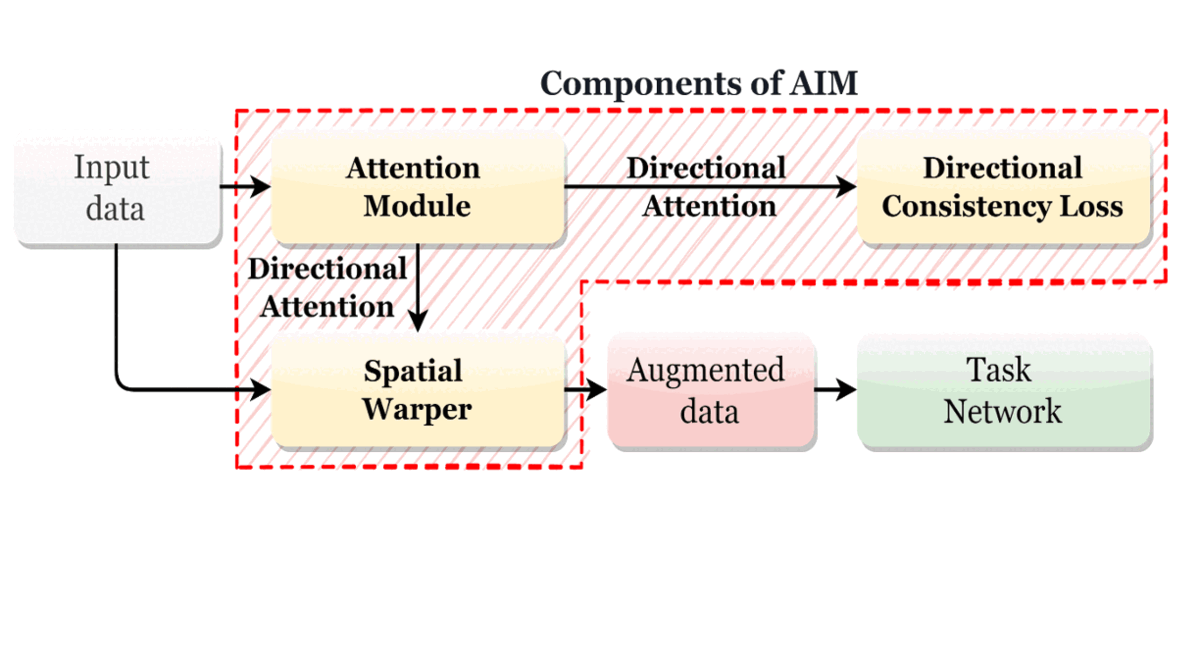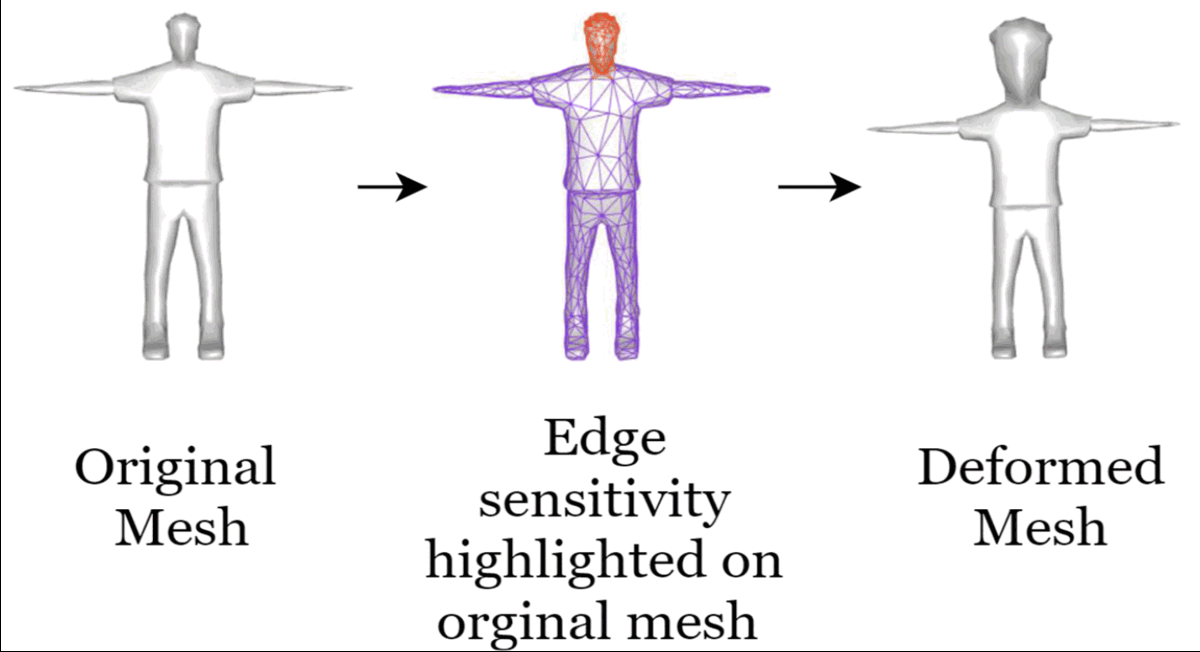
Data augmentations are commonly used to increase the robustness of deep neural networks. However, in most contemporary research, the networks do not decide the augmentations; they are task-agnostic, and grid search determines their magnitudes. Furthermore, augmentations applicable to lower-dimensional data do not easily extend to higher-dimensional data and vice versa. This paper presents an auto-augmenter for images and meshes (AIM) that easily incorporates into neural networks at training and inference times. It jointly optimizes with the network to produce constrained, non-rigid deformations in the data. AIM predicts sample-aware deformations suited for a task, and our experiments confirm its effectiveness with various networks. |

|
Different local neighborhoods on the object surface hold a different amount of geometric complexity. Applying the same data augmentation techniques at the object level is less effective in augmenting local neighborhoods with complex structures. This paper presents PatchAugment, a data augmentation framework to apply different augmentation techniques to the local neighborhoods. |
|
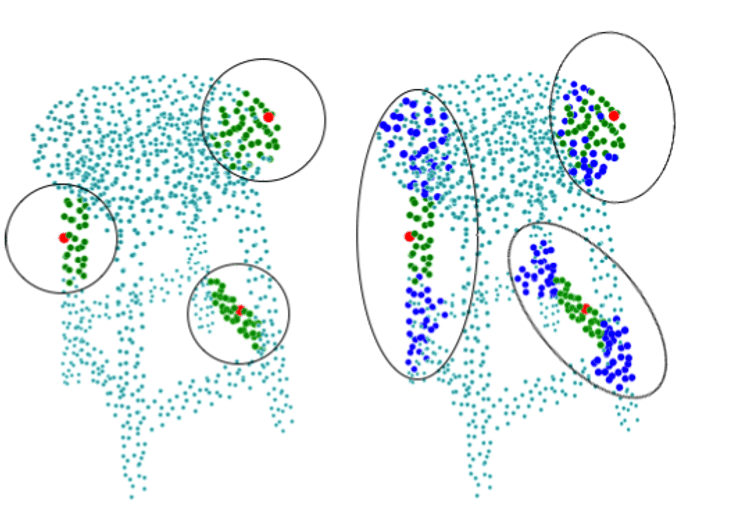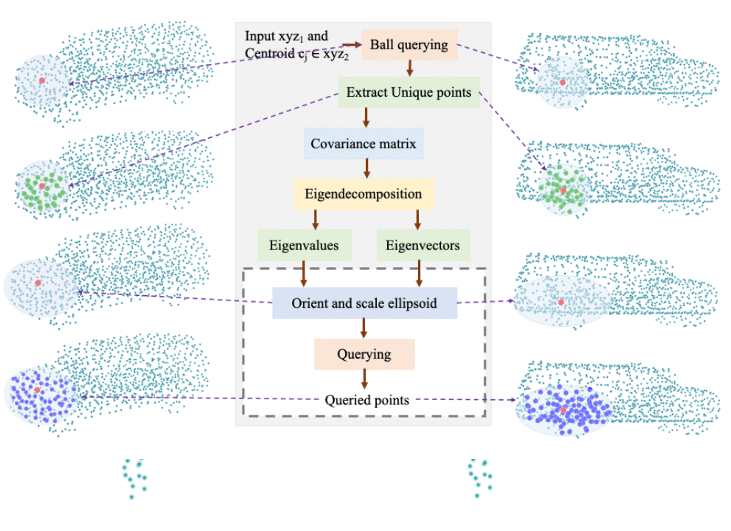
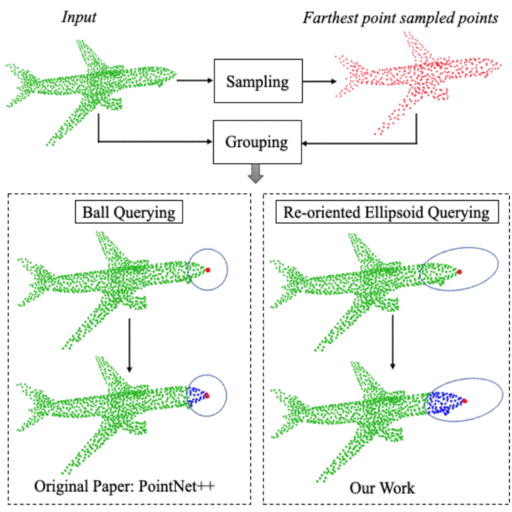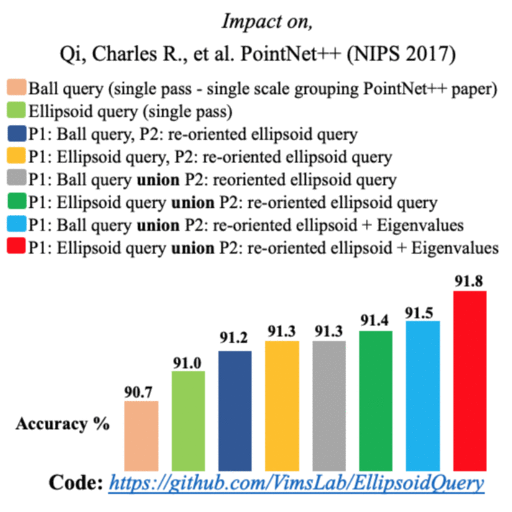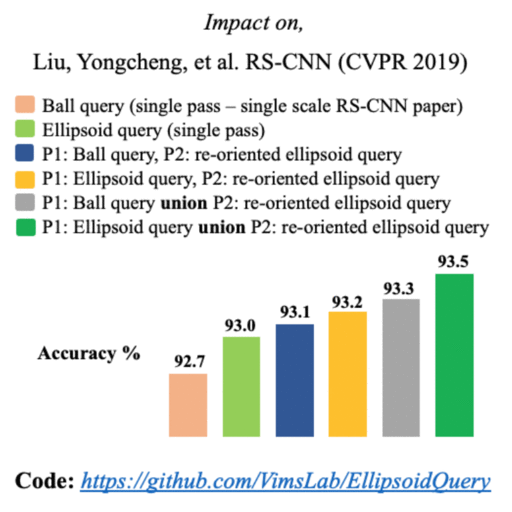
PointNet++ model uses ball querying for local geometry capture in its set abstraction layers. Several models based on single scale grouping of PointNet++ continue to use ball querying with a fixed-radius ball. However, ball lacks orientation and is ineffective in capturing complex or varying geometry proportions from different local neighborhoods on the object surface. We propose a novel technique of dynamically oriented and scaled ellipsoid based on unique local information to capture the local geometry better. We also propose ReducedPointNet++, a single set abstraction based single scale grouping model. |

|
In this paper, inspired by dilated convolutions for images, we proffer dilated convolutions for meshes. Our Dilated Mesh Convolution (DMC) unit inflates the kernels' receptive field without increasing the number of learnable parameters. We also propose a Stacked Dilated Mesh Convolution (SDMC) block by stacking DMC units. We accommodated SDMC in MeshNet to classify 3D meshes. |

|
MeshNet is a pioneer in this direction. In this paper, we propose a novel neural network that is substantially deeper than its MeshNet predecessor. This increase in depth is achieved through our specialized convolution and pooling blocks that operate on mesh faces. Our network named MeshNet++ learns local structures at multiple scales and is also robust to shortcomings of mesh decimation. We evaluated it for the shape classification task on various data sets, and results significantly higher than state-of-the-art were observed. |
|
Few of the recent deep learning models for 3D point sets classification are dependent on how well the model captures the local geometric structures. PointNet++ model was able to extract the local region features from points by ball querying the local neighborhoods. However, ball querying is less effective in capturing local neighborhoods of high curvature surfaces or regions. In this paper, we demonstrate improvement in the 3D classification results by using ellipsoid querying around centroids, capturing more points in the local neighborhood. We extend the ellipsoid querying technique by orienting it in the direction of principal axes of the local neighborhood for better capture of the local geometry. |